ThingsBoard规则引擎探究和学习
什么是Actor模型
探究ThingsBoard之前,需要先了解Actor(演员)模型:
在电脑科学中,演员模型(英语:Actor model)是一种并发运算上的模型。“演员”是一种程序上的抽象概念,被视为并发运算的基本单元:当一个演员接收到一则消息,它可以做出一些决策、创建更多的演员、发送更多的消息、决定要如何回答接下来的消息。演员可以修改它们自己的私有状态,但是只能通过消息间接的相互影响(避免了基于锁的同步) -- wikipedia
在函数方法执行模式上,该模型与传统的面向对象的OOP模型不同。
OOP中方法调用是通过线程在不同对象的方法中进栈和出栈实现的,如下图:

对象涉及多线程调用时,就需要使用锁机制,避免单个对象的内在状态同时被多个线程修改而引发逻辑异常,未获取锁的线程就处于阻塞状态,浪费了系统资源,如下图:
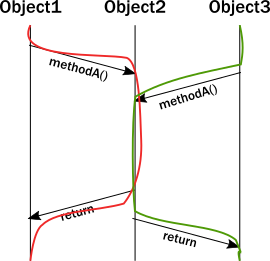
actor模型引入了acotr单元的概念,每个actor又通过mailbox邮箱机制进行消息通信,同一时间,actor只能处理一个消息,就不存在多线程竞争。
以饭馆作为例子,传统的线程执行模型类似于一个人(线程)从洗菜-烧菜-出菜都是顺序的一步步执行的,而actor模型类似于将洗菜,烧菜,出菜都独立成一个actor,各自通过查看mailbox中是否有任务消息;洗菜actor接收到洗菜任务的消息后,执行洗菜,完成后将洗好菜的消息传递出去。每个actor的执行都是从线程池中的多个线程来执行的。如下图所示:
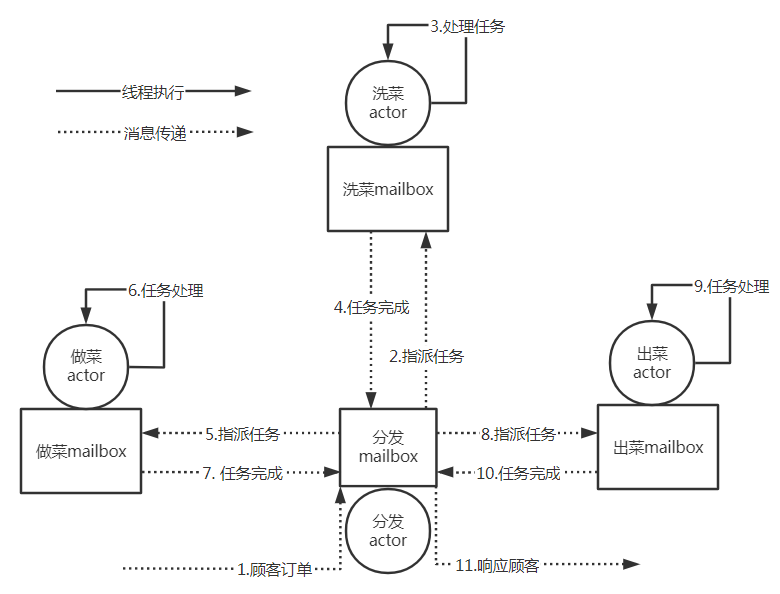
同一时间,actor只会存在一个线程来消费一个消息,每个actor都会对自己的邮箱进行轮询然后处理任务,可以改变其自身状态、发送新的消息或产生新的actor,因此actor节点中的逻辑都是单线程的,天然就有状态隔离和线程安全的优点,但是整个系统是多线程进行并发协同共同完成了一个业务的处理,这就提高了系统的并发能力,避免锁竞争的资源消耗。这样的执行模型方便进行分布式集群扩展,一个业务处理不一定是在单个机器中进完成,而是可以分发到多台机器,通过远程RPC调用,只要发送到对应的actor邮箱即可实现集群的并发计算。因此著名的分布式计算引擎Flink0.9版本开始引入akka框架,利用了akka实现的actor模型,来实现了分布式通信。
ThingsBoard中actor模型
ThingsBoard是一个开源物联网平台,工程产品化程度的较高,支持了多租户管理,其内部是通过Actor模型实现了高性能的处理架构,核心actor如下:
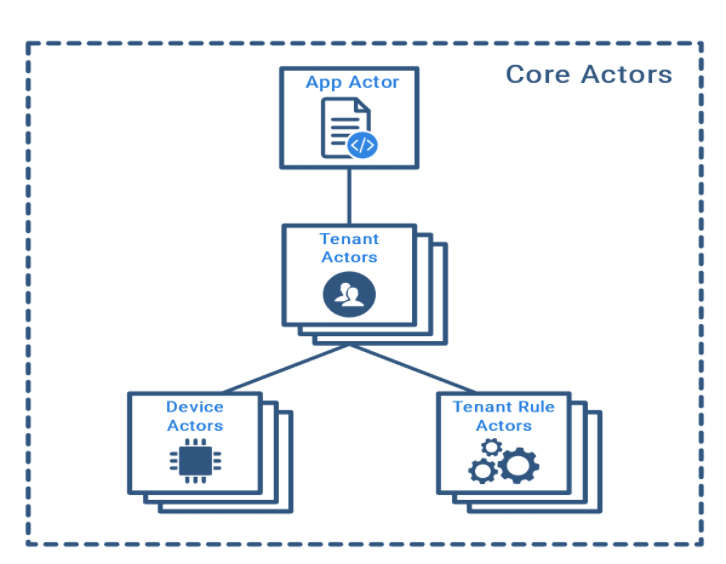
App Actor: 系统actor,负责管理租户actor,常驻内存
Tenant Actor: 租户actor,服务于对应租户,负责管理设备actor和规则actor
Device Actor: 设备actor,维护设备的状态,活动的Sessions, 订阅, 侦听RPC命令等
Rule Chain Actor: 规则链actor, 负责规则引擎的某个规则链
Rule Node Actor: 规则节点actor,负责规则引擎中某个逻辑节点
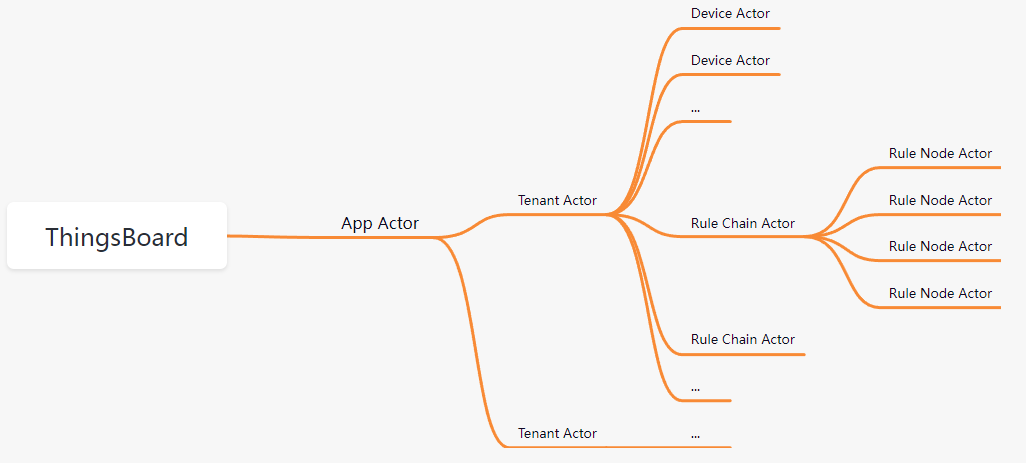
一个ThingsBoard实例只存在一个App actor,负责产生和管理多个租户actor,每个租户actor又会产生多个该租户下的设备Actor和规则actor,它们的层级结构如下:
ThingsBoard的规则引擎如何运行
这里我重点研究下ThingsBoard的规则引擎,它是如何执行运作的。
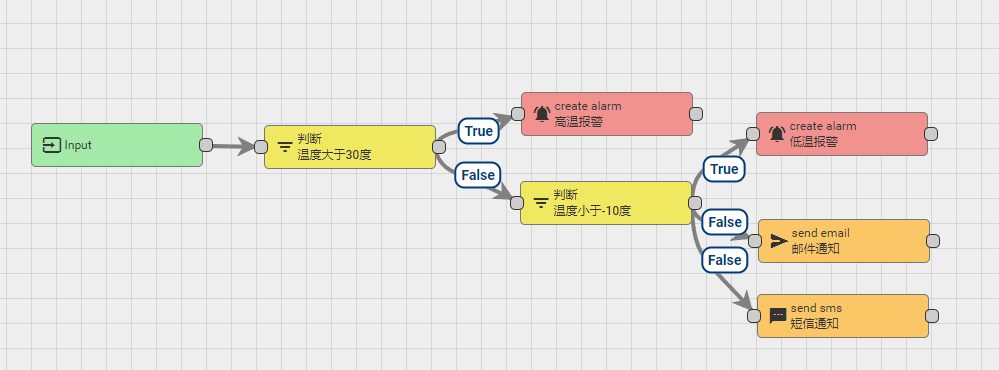
以上述简单的温度规则示例,规则引擎的逻辑可以是串行和并行的,取决于用户业务需求,因此,规则引擎执行时也需要满足并发执行场景。
以Actor模型的思维思考规则引擎:上述就是一个RuleChanActor对应一个规则链;这个规则链产生了多个RuleChainNode,它们各自(包括RuleChain)都有一个mailbox,每个节点执行的触发条件便是邮箱里有未读的消息,一旦poll轮询到了未读消息,就可以对消息进行处理,这时便会进入actor内部的逻辑,而且未读消息的消费是串行的,处理完成上一条后才可继续消费下一条,这样就实现了线程池中的多个线程可以执行多个节点的运算,但是单个节点一定是单线程在执行,保证了线程安全。每个actor默认一定会有Success执行成功和Failture失败两种情况,对应了程序中方法正常结束和异常抛出的场景;当然也可以在成功的基础上发送其他标签(如True/false)信息。
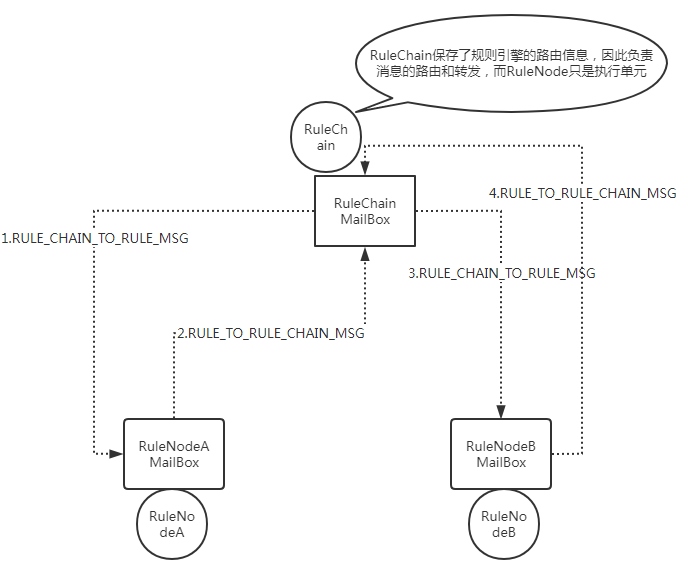
规则的执行依赖于消息的传递,如上图。RuleChainActor保存了节点之间的路由信息,每次节点执行的结果发回RuleChanActor,由RuleChainActor作为中心路由进行分发和流转,RuleChainNode只负责节点自身的逻辑。上述流程只示例了串行规则的场景,并发的场景同理,RuleChainActor会发送消息给多个RuleChainNode,因此消息对象必须是深拷贝,避免多个节点处理相同的消息会同时修改一个内存拷贝。
可以看到,Actor这样的异步模型比较依赖于消息的传递,对消息对象的优化就是执行模型的优化,因此ThindBoard在消息传递上使用了Protocol Buffers优化序列化和反序列化,提升信息密度,提高执行效果。
ps: 这里,我想到一个优化点,利用COW(Copy On Write)技术,在单独实例运行的规则链上,可以通过对消息对象类中做一定封装,当节点对msg修改时才进行深拷贝。
ThingsBoard规则引擎的集群策略
ThngsBoard支持集群部署,规则引擎在集群中执行时步骤:
- 以消息对象(msg)的触发来源(Orginator)作为partition key,来确定在集群中哪个partition进行规则的执行
- 目标partition如果是当前示例,就直接发送给对应actor的mailBox,否则就通过消息队列中间件发送到其他集群
消息对象msg在一个规则链中进行转发传递时,触发来源originator是一般都是固定的;因此,除非是在规则执行期间修改了originator(比如从设备触发修改为平台租户触发),否则同一个规则链的规则节点都是在同一个实例进行执行。
具体看下代码是如何决定目标分区的:
private TopicPartitionInfo resolve(ServiceQueue serviceQueue, TenantId tenantId, EntityId entityId) {
// UUID进行哈希,规则引擎中为消息的Originator(可以是外部请求,设备,用户等),通常在规则执行中不变
int hash = hashFunction.newHasher()
.putLong(entityId.getId().getMostSignificantBits())
.putLong(entityId.getId().getLeastSignificantBits()).hash().asInt();
Integer partitionSize = partitionSizes.get(serviceQueue);
int partition;
if (partitionSize != null) {
// 计算目标分区
partition = Math.abs(hash % partitionSize);
} else {
//TODO: In 2.6/3.1 this should not happen because all Rule Engine Queues will be in the DB and we always know their partition sizes.
partition = 0;
}
// 判断是否为租户隔离
boolean isolatedTenant = isIsolated(serviceQueue, tenantId);
TopicPartitionInfoKey cacheKey = new TopicPartitionInfoKey(serviceQueue, isolatedTenant ? tenantId : null, partition);
// 获取对应的partition或者是不存在则创建一个新的分区
return tpiCache.computeIfAbsent(cacheKey, key -> buildTopicPartitionInfo(serviceQueue, tenantId, partition));
}
获取到目标分区实例后,可以通过消息队列进行转发,ThingsBoard支持多种消息中间件,如Kafka、RabbitMQ、AWS SQS等。
每个实例会启动规则引擎的消费者,在线程池中定期向消息中间件中轮询poll消息,来消费其他实例发来的执行消息。
延伸阅读
关于ThingsBoard源码工程学习,可以参考以下仓库
how-2-use-thingsboard
关于Actor模型,可以参考其他资料:
The actor model in 10 minutes
Akka and Actors
How the Actor Model Meets the Needs of Modern, Distributed Systems